Spark Dataframe Examples: Window Functions
Last updated:Table of Contents
- Get aggregated values in group
- Where row is largest in group
- Where row in most recent date in group
- Get median value
- Get percentile value
- Cumulative sum
- Get row number/rank
- Row number / rank in partition
View all examples on this jupyter notebook
Window functions are often used to avoid needing to create an auxiliary dataframe and then joining on that.
Get aggregated values in group
Template: .withColumn(<col_name>, mean(<aggregated_column>) over Window.partitionBy(<group_col>))
Example: get average price for each device type
import java.sql.Date
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.functions._
val devicesDf = Seq(
(Date.valueOf("2019-01-01"), "notebook", 600.00),
(Date.valueOf("2019-05-10"), "notebook", 1200.00),
(Date.valueOf("2019-03-05"), "small phone", 100.00),
(Date.valueOf("2019-02-20"), "camera",150.00),
(Date.valueOf("2019-01-20"), "small phone", 300.00),
(Date.valueOf("2019-02-15"), "large phone", 700.00),
(Date.valueOf("2019-07-01"), "camera", 300.00),
(Date.valueOf("2019-04-01"), "small phone", 50.00)
).toDF("purchase_date", "device", "price")
devicesDf
.withColumn("average_price_in_group", mean("price") over Window.partitionBy("device"))
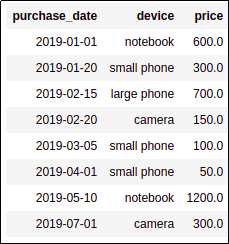 BEFORE: source dataframe
BEFORE: source dataframe
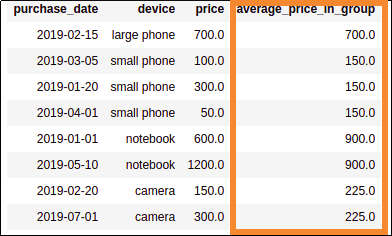 AFTER: added a column with the average price
AFTER: added a column with the average price of devices for each device type
Where row is largest in group
Example: Select the rows where the device price is the largest price for that device
import java.sql.Date
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.functions._
val devicesDf = Seq(
(Date.valueOf("2019-01-01"), "notebook", 600.00),
(Date.valueOf("2019-05-10"), "notebook", 1200.00),
(Date.valueOf("2019-03-05"), "small phone", 100.00),
(Date.valueOf("2019-02-20"), "camera",150.00),
(Date.valueOf("2019-01-20"), "small phone", 300.00),
(Date.valueOf("2019-02-15"), "large phone", 700.00),
(Date.valueOf("2019-07-01"), "camera", 300.00),
(Date.valueOf("2019-04-01"), "small phone", 50.00)
).toDF("purchase_date", "device", "price")
devicesDf
.withColumn("max_price_in_group", max("price") over Window.partitionBy("device"))
.filter($"price" === $"max_price_in_group")
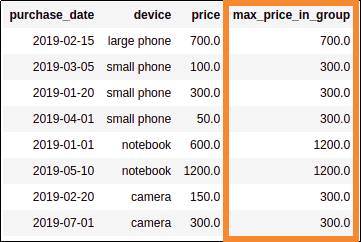 Generate a column with the maximum
Generate a column with the maximum price in each partition (that is,
for each device type)
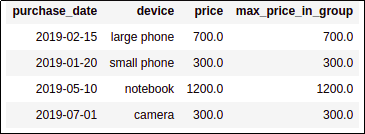 Then select rows where the price match
Then select rows where the price match the maximum price for that partition
Where row in most recent date in group
import java.sql.Date
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.functions._
val devicesDf = Seq(
(Date.valueOf("2019-01-01"), "notebook", 600.00),
(Date.valueOf("2019-05-10"), "notebook", 1200.00),
(Date.valueOf("2019-03-05"), "small phone", 100.00),
(Date.valueOf("2019-02-20"), "camera",150.00),
(Date.valueOf("2019-01-20"), "small phone", 300.00),
(Date.valueOf("2019-02-15"), "large phone", 700.00),
(Date.valueOf("2019-07-01"), "camera", 300.00),
(Date.valueOf("2019-04-01"), "small phone", 50.00)
).toDF("purchase_date", "device", "price")
devicesDf
.withColumn("most_recent_purchase_in_group", max("purchase_date") over Window.partitionBy("device"))
.filter($"purchase_date" === $"most_recent_purchase_in_group")
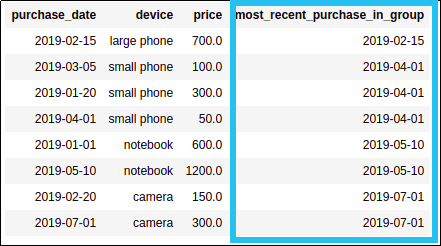 Generate a column with the most
Generate a column with the most recent date in each group
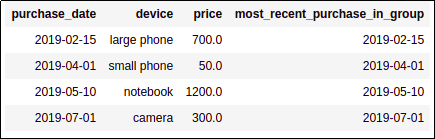 And filter where the purchase date is
And filter where the purchase date isequal to the most recent date in that group
Get median value
Example: get row whose price is the median value
import java.sql.Date
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.functions._
val devicesDf = Seq(
(Date.valueOf("2019-01-01"), "notebook", 600.00),
(Date.valueOf("2019-05-10"), "notebook", 1200.00),
(Date.valueOf("2019-03-05"), "small phone", 100.00),
(Date.valueOf("2019-02-20"), "camera",150.00),
(Date.valueOf("2019-01-20"), "small phone", 300.00),
(Date.valueOf("2019-02-15"), "large phone", 700.00),
(Date.valueOf("2019-07-01"), "camera", 300.00),
(Date.valueOf("2019-04-01"), "small phone", 50.00)
).toDF("purchase_date", "device", "price")
devicesDf
.withColumn("percentile", percent_rank() over Window.orderBy("price"))
.filter($"percentile" >= 0.5)
.limit(1)
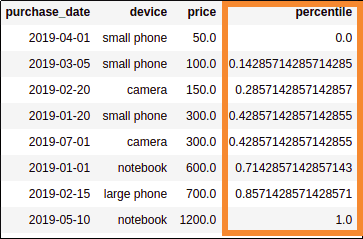 Add column with percentage values
Add column with percentage values
 And filter where
And filter where percentile >= 0.5
Get percentile value
Example: Get the row whose price surpasses the 85th percentile
import java.sql.Date
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.functions._
val devicesDf = Seq(
(Date.valueOf("2019-01-01"), "notebook", 600.00),
(Date.valueOf("2019-05-10"), "notebook", 1200.00),
(Date.valueOf("2019-03-05"), "small phone", 100.00),
(Date.valueOf("2019-02-20"), "camera",150.00),
(Date.valueOf("2019-01-20"), "small phone", 300.00),
(Date.valueOf("2019-02-15"), "large phone", 700.00),
(Date.valueOf("2019-07-01"), "camera", 300.00),
(Date.valueOf("2019-04-01"), "small phone", 50.00)
).toDF("purchase_date", "device", "price")
devicesDf
.withColumn("percentile", percent_rank() over Window.orderBy("price"))
.filter($"percentile" >= 0.85)
.limit(1)
 And get the first row whose percentile
And get the first row whose percentile is larger than the required 0.85
Cumulative sum
Example: cumulative sum for price column
import java.sql.Date
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.functions._
val devicesDf = Seq(
(Date.valueOf("2019-01-01"), "notebook", 600.00),
(Date.valueOf("2019-05-10"), "notebook", 1200.00),
(Date.valueOf("2019-03-05"), "small phone", 100.00),
(Date.valueOf("2019-02-20"), "camera",150.00),
(Date.valueOf("2019-01-20"), "small phone", 300.00),
(Date.valueOf("2019-02-15"), "large phone", 700.00),
(Date.valueOf("2019-07-01"), "camera", 300.00),
(Date.valueOf("2019-04-01"), "small phone", 50.00)
).toDF("purchase_date", "device", "price")
// a partitionby clause is not necessary,
// but the window must be ordered so that spark knows
// how to accumulate the sum
devicesDf
.withColumn("cumulative_sum", sum("price") over Window.orderBy("purchase_date"))
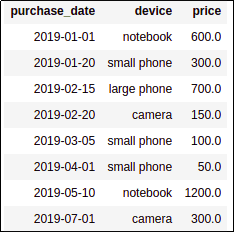 BEFORE: source dataframe
BEFORE: source dataframe
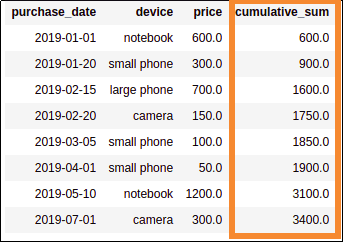 AFTER: added a column with the cumulative price sum
AFTER: added a column with the cumulative price sum
Get row number/rank
row_numberstarts at 1!
import java.sql.Date
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.functions._
val devicesDf = Seq(
(Date.valueOf("2019-01-01"), "notebook", 600.00),
(Date.valueOf("2019-05-10"), "notebook", 1200.00),
(Date.valueOf("2019-03-05"), "small phone", 100.00),
(Date.valueOf("2019-02-20"), "camera",150.00),
(Date.valueOf("2019-01-20"), "small phone", 300.00),
(Date.valueOf("2019-02-15"), "large phone", 700.00),
(Date.valueOf("2019-07-01"), "camera", 300.00),
(Date.valueOf("2019-04-01"), "small phone", 50.00)
).toDF("purchase_date", "device", "price")
// a partitionby clause is not necessary,
// but the window must be ordered so that spark knows
// how to order the row count
devicesDf
.withColumn("row_number", row_number() over Window.orderBy("purchase_date"))
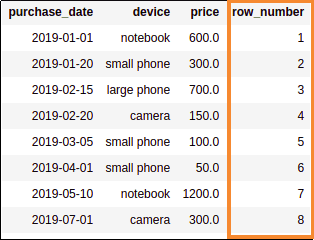 AFTER: Added a column with the matching row number
AFTER: Added a column with the matching row number
Row number / rank in partition
Same thing as above, but with an added partitionBy at the end
import java.sql.Date
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.functions._
val devicesDf = Seq(
(Date.valueOf("2019-01-01"), "notebook", 600.00),
(Date.valueOf("2019-05-10"), "notebook", 1200.00),
(Date.valueOf("2019-03-05"), "small phone", 100.00),
(Date.valueOf("2019-02-20"), "camera",150.00),
(Date.valueOf("2019-01-20"), "small phone", 300.00),
(Date.valueOf("2019-02-15"), "large phone", 700.00),
(Date.valueOf("2019-07-01"), "camera", 300.00),
(Date.valueOf("2019-04-01"), "small phone", 50.00)
).toDF("purchase_date", "device", "price")
devicesDf
.withColumn("row_number", row_number() over Window.partitionBy("device").orderBy("purchase_date"))
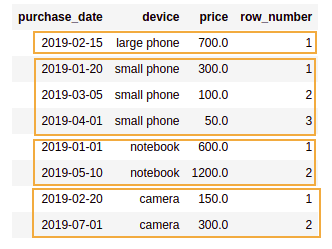 AFTER: Added a column with the matching row number
AFTER: Added a column with the matching row number inside each partition