Paper Summary: Sequence to Sequence Learning with Neural Networks
Last updated:Please note This post is mainly intended for my personal use. It is not peer-reviewed work and should not be taken as such.
WHAT
Authors devise an architecture that enables learning of arbitrary maps between input and output sequences.
The well-known encoder-decoder pattern for sequence learning is introduced in this article.
They apply this architecture to the problem of Machine Translation (English to French).
WHY
Traditional DNNs are flexible and powerful but they require the dimensionality of inputs to be known and fixed.
For this reason they're unsuitable for use with sequences whose size can and does vary a lot.
HOW
The Seq2Seq model is made up of two parts:
Encoder:
- It's a Deep LSTM
- Maps the input vector from the input space into a fixed-length vector (embedding)
Decoder:
- Also a Deep LSTM
- Decodes the fixed-length vector created in part 1 into the output space.
They use a standard SGD optimizer to train the model.
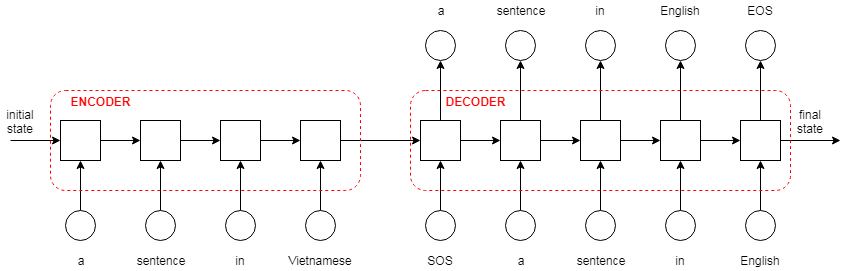 Overview of the encoder/decoder architecture,
Overview of the encoder/decoder architecture, as applied to machine translation.
Source: Machine talk
CLAIMS
- The LSTM-based encoder/decoder model outperformed a modern SMT model even though it only used a small number of words in the vocabulary.
QUOTES
If there is a task that humans can solve quickly, then there exists a DNN parameter configuration that solves it. Furthermore, this configuration can be found via backpropagation.
- This is a suprisingly strong claim here.
- Maybe the catch is: this only works if you can represent your problem using fixed-width vectors.
"Although LSTMs tend not to suffer from the vanishing gradient problem, they can have exploding gradients."
NOTES
The model used to obtain the results was trained using a relatively small vocabulary (80,000 words), suggesting that an even better performance can be attained using a larger vocabulary.
The input sentence are reversed prior to feeding into the encoder half of the network. Apparently it helps the optimizers converge to a solution faster.
The model creates very similar representations for active voice and passive voice versions of the same sentence.
They mention that one way to do MT using DNNs is to just take an off-the-shelf statistical machine translation (SMT) model and use a DNN-based Language Model to re-rank the top suggestions for translations given by the SMT model.
MY 2¢
- Authors mention question answering but they didn't realize that every NLP problem can be thought of as a type of question-answering (cf. The Natural Language Decathlon)