Comparing Interactive Solutions for Running Scala and Spark: Zeppelin, Spark-notebook and Jupyter-scala
Last updated:2019 UPDATE. jupyter-scala is now called almond. For a jupyter connection to a local spark cluster use apache toree. For enterprise notebooks on spark clusters you are probably better off using Databricks
A lot of exploratory work is often required to get a better idea of what our data looks like at a high level.
Spark is great both for batch- and streaming-oriented data pipelines but not a lot of attention has been given on how to perform exploratory data analysis and the general workflow involved in the process. Interactive tools are ideal for that task and also enable you to share your results with the community.
Interactive notebooks are ideal for exploring datasets and sharing results with the community
Another concept that has come up recently is that of data storytelling. A notebook file can be a great way to explain and document how you go from raw data to valuable information and insights.
So here are three of the top alternatives for notebook-like interfaces (made popular by Python among others) to Spark; all 3 of them were tested and I've tried to highlight the most important aspects of each, from a practitioner's point of view.
Zeppelin
Version Used: 0.56
| PROS | CONS |
|---|---|
| Good integration with Spark | No tab-completion |
| Available on AWS Elastic MapReduce (EMR) |
Apache Zeppelin is (as of April 2016) an incubating project at the ASF. As such, it still has some rough edges which are being dealt with. That said, it is perfectly possible to put it to productive use.
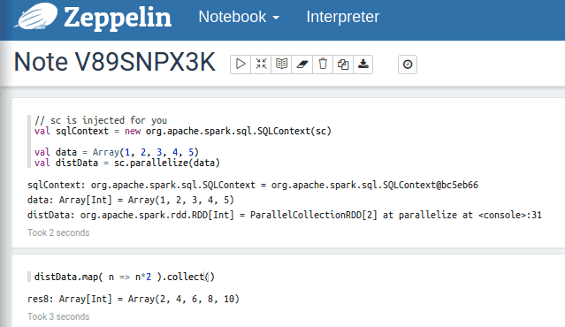 A Zeppelin notebook at work
A Zeppelin notebook at work
It is sometimes a little bit slow to respond, particularly when dealing with large amounts of data.
Features
Supports Pyspark as well as Scala
It is available out of the box on AWS Elastic MapReduce (EMR) for newer cluster configurations (emr-4.1.0 or newer)
It supports Spark Streaming, which is very useful because streaming applications take some debugging and maybe trial and error to ensure your logic is correct.
It actually supports many other backends (called interpreters) such as Cassandra, Elasticsearch, Hive, among others.
Some (limited) charting is available for SparkSQL queries
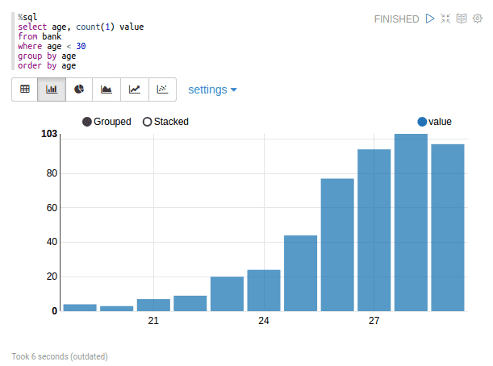 Zeppelin provides basic charting functionality but it is somewhat complicated: it requires that you have your data as a DataFrame, then register it as a temporary table and then query it using its %sql interpreter, or it doesn't work
Zeppelin provides basic charting functionality but it is somewhat complicated: it requires that you have your data as a DataFrame, then register it as a temporary table and then query it using its %sql interpreter, or it doesn't work
Spark-notebook
Version used: 0.6.3
| PROS | CONS |
|---|---|
| Very good integration with Spark | A lot of functionality, feels a little bloated |
| Tab-completion available | |
| Easy set up: download, extract and run | |
| Comes with tons of examples | |
| Lots of charting capabilities |
It's clear that a lot of work has gone into Spark notebook. It's quite complete, going beyond than what you would expect from a notebook with Spark support.
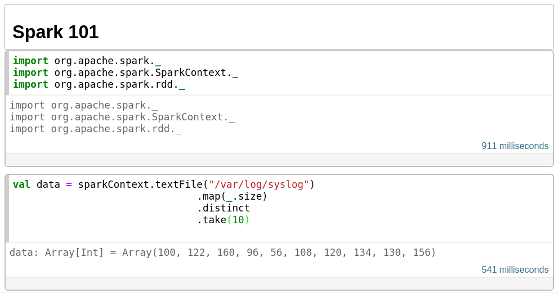 Doing basic Spark operations on spark-notebook is easy enough
Doing basic Spark operations on spark-notebook is easy enough
There are so many auxiliary features it's actually a little bit confusing to discover everything it can do. In addition to working with Spark interactively, here's a sample of other things you can do:
Run shell commands from the notebook (for example to download files using
wget)Have streaming data come in (via Spark Streaming) and feed a live javascript-based chart
Use complex javascript libraries (such as D3.js, Leaflet, Rickshaw) in your notebook
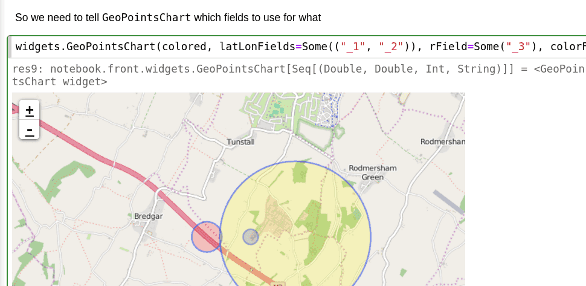 In the Geo Data example (included in the download) you can handle GeoJson data and project it over a map using the Leaflet javascript framework
In the Geo Data example (included in the download) you can handle GeoJson data and project it over a map using the Leaflet javascript framework
Jupyter-scala
Version used: 0.2.0-SNAPSHOT
Jupyter-scala is now called almond
| PROS | CONS |
|---|---|
| Notebooks saved as .ipynb | Has some minor bugs |
| Tab-completion available | |
| Easy set up | |
| No frills, just basic functionality |
Jupyter-scala is an adaptation of the popular jupyter notebook system for Python.
After installing (see link above), you should see an extra kernel available when you create new notebooks using Jupyter; after all, jupyter-scala is just another kernel (or backend) that you add to jupyter.
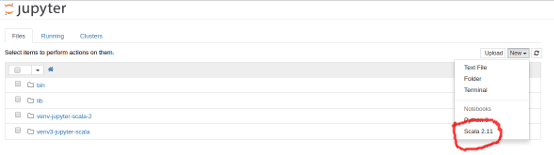 If installation was OK, you should see a Scala kernel when you create a new jupyter notebook
If installation was OK, you should see a Scala kernel when you create a new jupyter notebook
Features
Works like the console you get when you type
scalaorsbt consoleon your shellIt's a very thin layer on top of jupyter
You can download maven packages from within the notebook itself, with a command like
load.ivy("org.json4s" % "json4s-jackson_2.11" % "3.3.0")(you may get a few error messages but the packages still get downloaded)
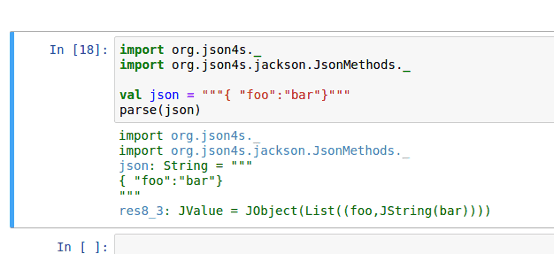 It looks similar to the regular console
It looks similar to the regular console
Verdict
Use jupyter-scala if you just want a simple version of jupyter for Scala (no Spark).
Use spark-notebook for more advanced Spark (and Scala) features and integrations with javascript interface components and libraries;
Use Zeppelin if you're running Spark on AWS EMR or if you want to be able to connect to other backends.