Apache Spark Examples: Dataframe and Column Aliasing
Last updated:- reference XYZ is ambiguous
- Add alias to dataframe
- Show column names with alias
- Heads-up: .drop() removes all instances
WIP Alert This is a work in progress. Current information is correct but more content may be added in the future.
Spark version 2.4.8 used unless otherwise stated!
All code can be found on this jupyter notebook
reference XYZ is ambiguous
reference XYZ is ambiguous. It could be ... or...
This is the error message you get when you try to reference a column that exists in more than one dataframe.
In order to fix this, add aliases to the dataframes you are working with so that the query planner can know which dataframe you are referencing.
Add alias to dataframe
You have two dataframes you want to join. But both of them have a column named device_id: 1
Use as("new_name") to add an alias to a dataframe:
import java.sql.Date
import org.apache.spark.sql.functions._
val purchasesDF = Seq(
(Date.valueOf("2019-01-01"), "01"),
(Date.valueOf("2019-05-10"), "01"),
(Date.valueOf("2019-03-05"), "02"),
(Date.valueOf("2019-02-20"), "03"),
(Date.valueOf("2019-01-20"), "02")
).toDF("purchase_date", "device_id")
val devicesDF = Seq(
("01", "notebook", 600.00),
("02", "small phone", 100.00),
("03", "camera",150.00),
("04", "large phone", 700.00)
).toDF("device_id", "device_name", "price")
// THIS THROWS AN ERROR:
// Reference 'device_id' is ambiguous, could be: device_id, device_id.;
purchasesDF
.join(devicesDF, col("device_id") === col("device_id"))
// ADDING AN ALIAS TO BOTH DFs
purchasesDF.as("purchases")
.join(devicesDF.as("devices"), col("purchases.device_id") === col("devices.device_id"))
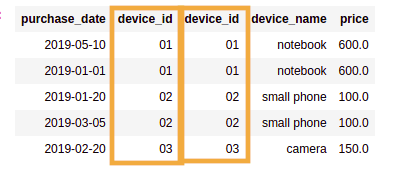 GREAT: you were able to reference the columns
GREAT: you were able to reference the columns in the query, but now how can you
which is which?
Show column names with alias
I could not find any way to obtain this information but you can trigger an AnalysisException by selecting an inexisting column:
The exception message will contain the fully qualified column names:2
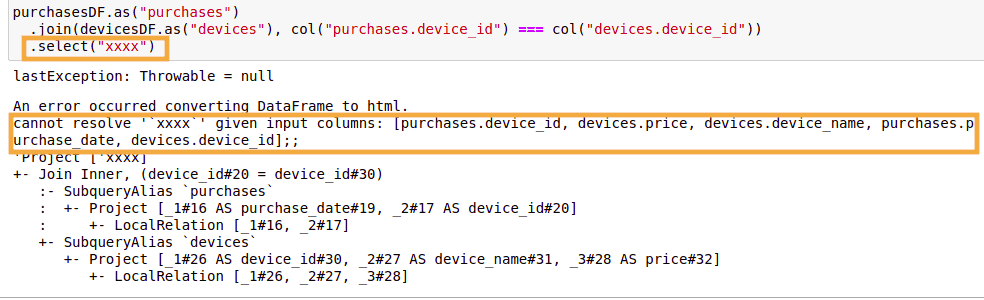 Hacky approach: by triggering an
Hacky approach: by triggering an AnalysisException, you will be able to view the fully qualified column names
in the Exception message
Heads-up: .drop() removes all instances
import java.sql.Date
import org.apache.spark.sql.functions._
val purchasesDF = Seq(
(Date.valueOf("2019-01-01"), "01"),
(Date.valueOf("2019-05-10"), "01"),
(Date.valueOf("2019-03-05"), "02"),
(Date.valueOf("2019-02-20"), "03"),
(Date.valueOf("2019-01-20"), "02")
).toDF("purchase_date", "device_id")
val devicesDF = Seq(
("01", "notebook", 600.00),
("02", "small phone", 100.00),
("03", "camera",150.00),
("04", "large phone", 700.00)
).toDF("device_id", "device_name", "price")
// DROP will remove BOTH columns!
purchasesDF.as("purchases")
.join(devicesDF.as("devices"), col("purchases.device_id") === col("devices.device_id"))
.drop("device_id")
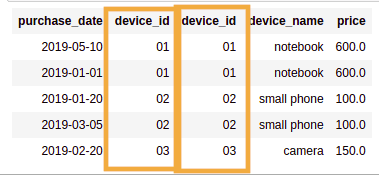 BEFORE: After a join with aliases, you end
BEFORE: After a join with aliases, you end up with two columns of the same name
(they can still be uniquely referenced by the alias)
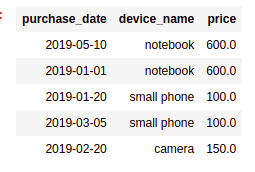 AFTER: calling
AFTER: calling .drop() drops both columns!
1: In this case you could avoid this problem by using Seq("device_id") instead, but this isn't always possible.
2: At the time of this writing, this is apparently how the AnalysisException obtains the qualified column name to display in the error message. With my limited knowledge of spark internals, this seems to be a piece of information that is only available after the query planner has compiled the query - this may be why it's not possible to obtain at query-writing time.